Note: This is a cross-post from the Boris Tyukin’s personal blog Building Near Real-time Big Data Lake: Part 2
This is the second part of the series. In Part 1 I wrote about our use-case for the Data Lake architecture and shared our success story.
Requirements
Before we embarked on our journey, we had identified high-level requirements and guiding principles. It is crucial to think it through to envision who and how will use your Data Lake. Identify your first three projects to keep them while you are building the Data Lake.
The best way is to start a few smaller proof-of-concept projects: play with various distributed engines and tools, run tons of benchmarks, and learn from others, who implemented a similar solution successfully. Do not forget to learn from others’ mistakes too.
We had settled on these 7 guiding principles before we started looking at technology and architecture:
- Scale-out, not scale-up.
- Design for resiliency and availability.
- Support both real-time and batch ingestion into a Data Lake.
- Enable both ad-hoc exploratory analysis as well as interactive queries.
- Replicate in near real-time 300+ Cerner Millennium tables from 3 remote-hosted Cerner Oracle RAC instances with average latency less than 10 seconds (time between a change made in Cerner EHR system by clinicians and data ingested and ready for consumption in Data Lake).
- Have robust logging and monitoring processes to ensure reliability of the pipeline and to simplify troubleshooting.
- Reduce manual work greatly and ease the ongoing support.
We decided to embrace the benefits and scalability of Big Data technology. In fact, it was a pretty easy sell as our leadership was tired of constantly buying expensive software and hardware from big-name vendors and not being able to scale-out to support an avalanche of new projects and requests.
We started looking at Change Data Capture (CDC) products to mine and ship database logs from Oracle.
We knew we had to implement a metadata- or code-as-configuration driven solution to manage hundreds of tables, without expanding our team.
We needed a flexible orchestration and scheduling tool, designed with real-time workloads in mind.
Finally, we engaged our and Cerner’s leadership early, as it would take time to hash out all the details, and to make their DBAs confident that we were not going to break their production systems by streaming 1000s of messages every second 24x7. In fact, one of the goals was to relieve production systems from analytical workloads.
Platform selection
First off, we had to decide on the actual platform. After spending 3 months researching, 4 options emerged, given the realities of our organization:
- On-premises virtualized cluster, using preferred vendors, recommended by our infrastructure team.
- On-premises Big Data appliance (bundled hardware and software, optimized for Big Data workloads).
- Big Data cluster in cloud, managed by ourselves (IaaS model, which just means renting a bunch of VMs and running Cloudera or Hortonworks Big Data distribution).
- A fully managed cloud data platform and native cloud data warehouse (Snowflake, Google BigQuery, Amazon Redshift, and etc.)
Each option had a long list of pros and cons, but ultimately we went with option 2. The price was really attractive, it was a capital expense (our finance people rightfully hate subscriptions), the best performance, security, and control.
It was in 2017 when we made a decision. While we could not provision cluster resources and add nodes with a click of button and we learned that software and hardware upgrades were a real chore, it was still very much worth that as we’ve saved a 7 number figure for the organization to get the performance we needed.
Owning hardware also made a lot of sense for us as we could not forecast our needs far enough in the future and we could get a really powerful 6 node cluster for a fraction the cost that we would end up paying in subscription fees in the next 12 months. Of course, it did help that we already had a state-of-the-art data center and people managing it.
Fully-managed or serverless architecture was not really an option back then, but if you asked me today, this would be the first thing I would look at if I had to build a data lake today (definitely check AWS Lake Formation, AWS Athena, Amazon Redshift, Azure Synapse, Snowflake and Google BigQuery).
Your organization, goals, projects and situation could be very different and you should definitely evaluate cloud solutions, especially in 2020 when prices are decreasing, cloud providers are extremely competitive and there are new attractive pricing options with 3 year commitment. Make sure you understand the cost and billing model. Or, hire a company (there are plenty now), that will explain your cloud bills before you get a horrifying check.
Some of the things to consider:
- Existing data center infrastructure and access to people, supporting it.
- Integration with current tools (BI, ETL, Advanced Analytics etc.) Do they stay on-premises or can be moved into cloud to avoid networking lags or charges for data egress?
- Total ownership cost and cost to performance ratio.
- Do you really need elasticity? This is the first thing that cloud advocates are preaching but think if and how this applies to you.
- Is time-to-market so crucial for you, or you can wait a few months to build Big Data infrastructure on-premises to save some money and get much better performance and control of physical hardware?
- Are you okay with locking yourself in to vendor’s solution XYZ? This is an especially crucial question if you are selecting a fully managed platform.
- Can you easily change your cloud provider? Or can you even afford to put all your trust and faith in a single cloud provider?
Do your homework, spend a lot of time reading and talking to other people (engineers and architects, not sales reps), and make sure you understand what you are signing up for.
And remember, there is no magic! You still need to architect, design, build, support, test, and make good choices and use common sense. No matter what your favorite vendor tells you. You might save time by spinning up a cluster in minutes, but you still need people to manage all that. You still need great architects and engineers to realize benefits from all that hot new tech.
Building blocks
Once we agreed on the platform of our choice, powered by Cloudera Enterprise Data Hub, we started prototyping and benchmarking various engines and tools that came with it. We looked at other open-source projects, as nothing really prevents you from installing and using any open-source product you desire and trust. One of these products for us was Apache NiFi, which proved to be a tremendous value.
After a lot of trials and errors, we decided on this architecture:
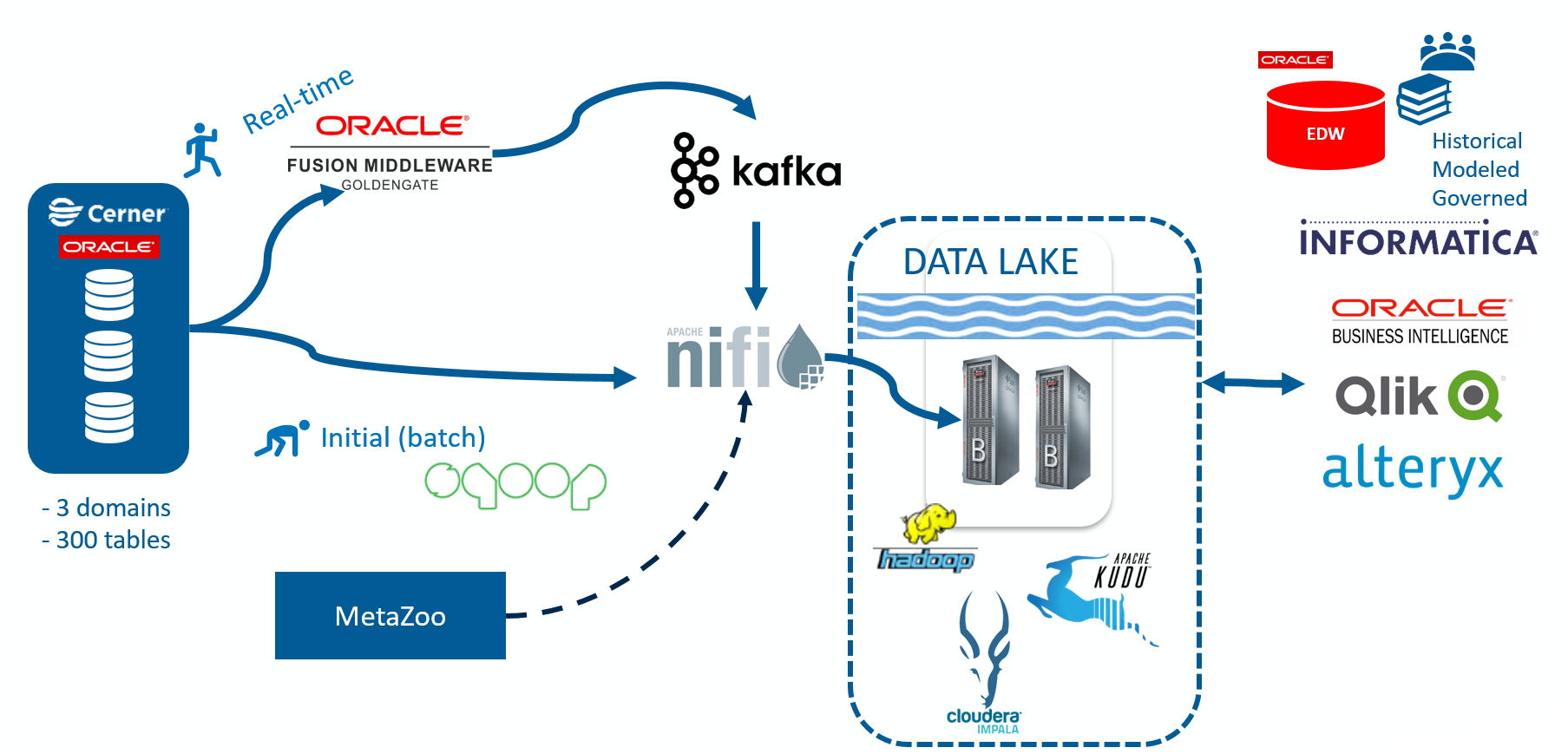
One of the toughest challenges we faced right away was the fact that most of the Big Data data engines were not designed to support mutable data but rather immutable append-only data. All the workarounds we had tried did not work for us and no matter what we did with partitioning strategy, we just needed a simple ability to update and delete data, not only insert. Anyone who worked with RDBMS or legacy columnar databases takes this capability for granted, but surprisingly it is a very difficult task in Big Data world.
We considered Apache HBase, but the performance of analytics-style ETL and interactive queries was really bad. We were blown away by Apache Impala’s performance on HDFS as no matter what we threw at Impala, it was hundreds of times faster…but we could not update data in place.
At about the same time, Cloudera released and open-sourced Apache Kudu project that became part of its official distribution. We got very excited about it (refer to our benchmarks here), and decided to proceed with Kudu as a storage engine, while using Apache Impala as SQL query engine. One of the ambitious goals of Apache Kudu is to cut the need for the infamous Lambda architecture.
After talking to 7 vendors and playing with our top picks, we selected a Change Data Capture product (Oracle GoldenGate for Big Data edition). It deserves a separate post but let’s just say it was the only product out of 7, that was able to handle complexities of the source Oracle RAC systems and offer great performance without the need to install any agents or software on the actual production database. Other solutions had a very long list of limitations for Oracle systems, make sure to read and understand these limitations.
Our homegrown tool MetaZoo has been instrumental to bring order and peace, and that’s why it earned its own blog post!
How it works
Initial ingest is pretty typical - we use Sqoop to extract data from Cerner Oracle databases, and NiFi helps orchestrate initial load for hundreds of tables. Actually, this NiFi flow below can handle initial ingest of hundreds of tables!
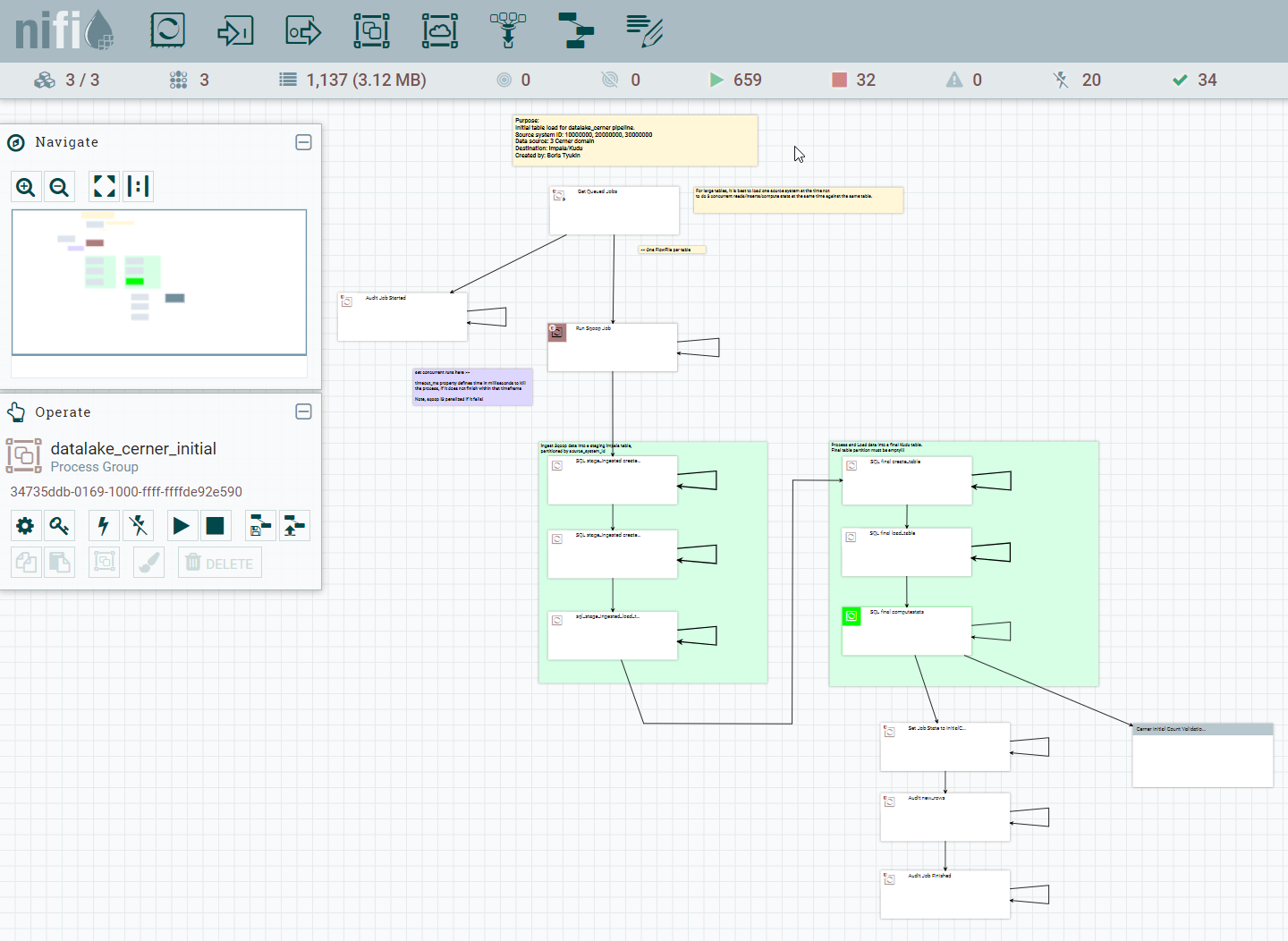
Our secret sauce though is MetaZoo. MetaZoo generates optimal parameters for Sqoop (such as a number of mappers, split-by column, and so forth), generates DDLs for staging and final tables, and SQL commands to transform data before they land in the Data Lake. MetaZoo also provides control tables to record status of every table.
The throughput of Sqoop is nothing but amazing. Gone are the days when we had to ask Cerner to dump tables on a hard-drive and ship it by snail mail (do not ask how much it cost us!). And we like how YARN queues help to limit the load on production databases.
To give you one example, a few years ago it took us 4 weeks to reload clinical_event table from
Cerner using Informatica into our local Oracle database. With Sqoop and Big Data, it was done in 11
hours!
This is what happens during the initial ingest.
First, MetaZoo gathers relevant metadata from source system about tables to ingest, and based on that metadata will generate DDL scripts, SQL commands snippets, Sqoop parameters, and more. It will initialize tables in MetaZoo control tables as well.
Then NiFi picks a list of tables to ingest from MetaZoo control tables and run the following steps to:
- Execute and wait for Sqoop to finish.
- Apply some basic rules to map data types to the corresponding data types in the lake. We convert timestamps to a proper time zone as well. While you do not want to do any heavy processing or or any data modeling in Data Lake and keep data closer to raw format as much as you can, some light processing upfront goes a long way and make it easier for analysts and developers to use these tables later.
- Load processed data into final tables after some basic validation.
- Compute Impala statistics.
- Set initial ingest status to completed in MetaZoo control tables so it is ready for real-time streaming.
Before we kick off the initial ingest process, we start Oracle GoldenGate extracts and replicats (that’s the actual term) to begin capturing changes from a database and send them into Kafka. Every message, depending on database operation type and GoldenGate configuration, might have before/after table row values, operation type and database commit transaction time (it only extracts changes for committed transactions). Once the initial ingest is finished, and because GoldenGate continues sending changes since the moment we started, we can now start real-time ingest flow in NiFi.
A side benefit of decoupling GoldenGate from Kafka and NiFi and Kudu is to make this process resilient to failures. This allows us as well to bring one of these systems down for maintenance without much impact.
Below is the NiFi flow than handles real-time streaming from Oracle/GoldenGate/Kafka and persists data into Kudu:
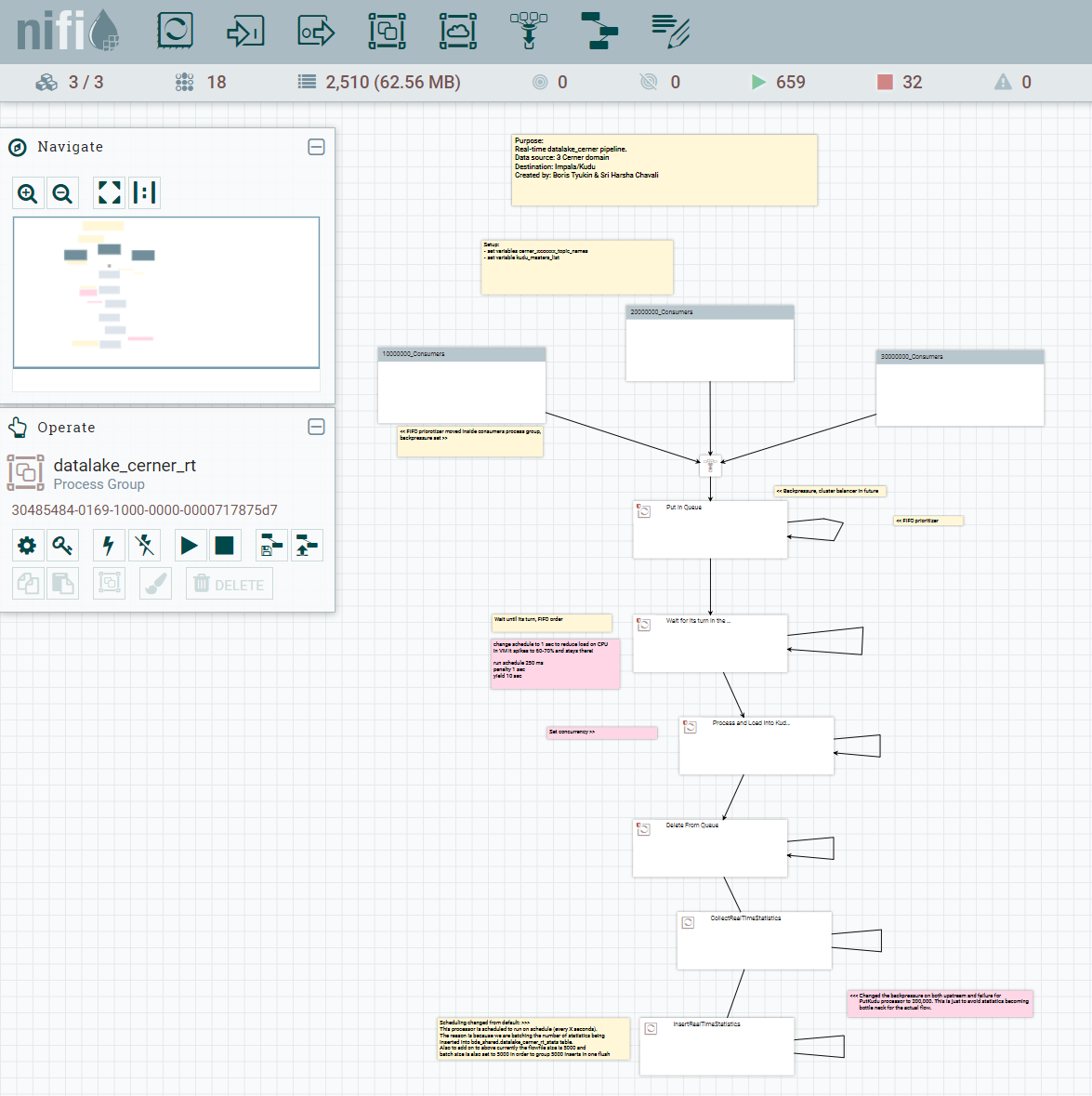
- NiFi flow consumes Kafka messages, produced by GoldenGate. Every table from every domain has its own Kafka topic. Topics have only one partition to preserve the original order of messages.
- New messages are queued in NiFi, using a simple First-In-First-Out pattern and grouped by a table. It is important to ensure the order of messages but still process tables concurrently.
- Messages are transformed, using the same basic rules we apply during the initial ingest.
- Finally, messages are persisted into Kudu. Some of them represent INSERT type operation, which results in brand new rows added to Kudu tables. Other messages are UPDATE and DELETE operations. And we have to deal with an exotic PK_UPDATE operation, when a primary key was changed for some reason in the source system (e.g. PK=111 was renamed to 222). We had to write a custom Kudu client to handle all these cases using Java Kudu API that was fun to use. NiFi allowed us to write custom processors and integrate that custom Kudu code directly into our flow.
- Useful metrics are stored in a separate Kudu table. We collect number of messages processed, operation type (insert, update, delete or primary key update), latency, important timestamps. Using this data, we can optimize and tweak the performance of the pipeline, and to monitor it by visualizing data on a dashboard.
The entire flow handles 900+ tables today (as we capture 300 tables from 3 Cerner domains).
We process ~2,000 messages per second or 125MM messages per day. GoldenGate accumulates 150Gb worth of database changes per day. In Kudu, we store over 120B rows of data.
Our average latency is 6 seconds and the pipeline is running 24x7.
User experience
I am biased, but I think this is a game-changer for analysts, BI developers, or any data people. What they get is an ability to access near real-time production data, with all the benefits and scalability of Big Data technology.
Here, I run a query in Impala to count patients, admitted to our hospitals within the last 7 days, who are still in the hospitals (not discharged yet):
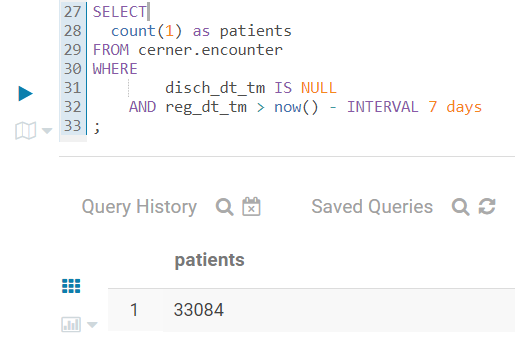
Then 5 seconds later I run the same query again to see numbers changed - more patients got admitted and discharged:
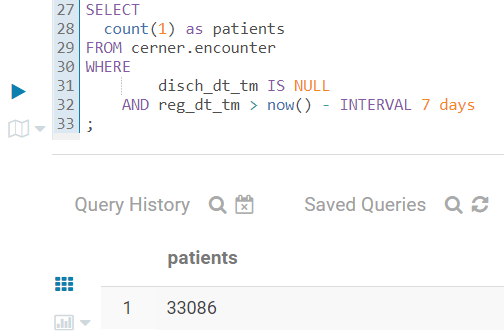 ]
]
This query below counts certain clinical events in the 20B row Kudu table (which is updated in near real-time). While it takes 28 seconds to finish, this query would never even finish I ran it against our Oracle database. It found 13.7B events:
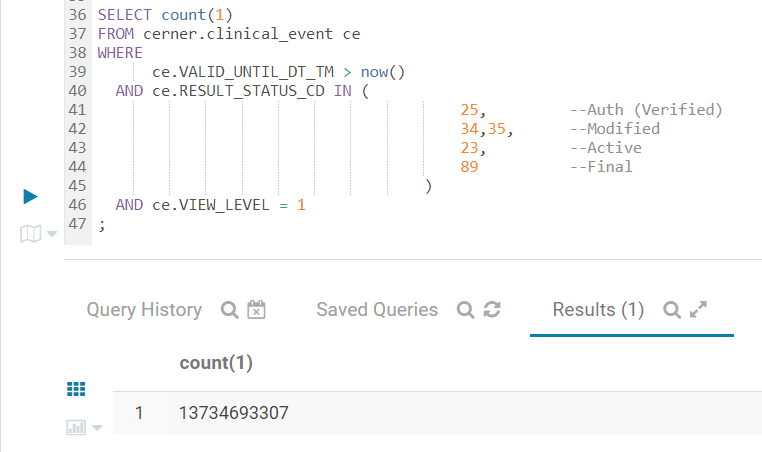
Credits
Apache Impala, Apache Kudu and Apache NiFi were the pillars of our real-time pipeline. Back in 2017, Impala was already a rock solid battle-tested project, while NiFi and Kudu were relatively new. We did have some reservations about using them and were concerned about support if/when we needed it (and we did need it a few times).
We were amazed by all the help, dedication, knowledge sharing, friendliness, and openness of Impala, NiFi and Kudu developers. Huge thank you to all of you who helped us alone the way. You guys are amazing and you are building fantastic products!
To be continued…