Apache Kudu Overview
Data Model
A Kudu cluster stores tables that look just like tables you're used to from relational (SQL) databases.
A table can be as simple as an binary key and value, or as complex
as a few hundred different strongly-typed attributes.
Just like SQL, every table has a PRIMARY KEY made up of one or more columns.
This might be a single column like a unique user identifier, or a compound key such as a
(host, metric, timestamp) tuple for a machine time series database. Rows can be efficiently
read, updated, or deleted by their primary key.
Kudu's simple data model makes it breeze to port legacy applications or build new ones: no need to worry about how to encode your data into binary blobs or make sense of a huge database full of hard-to-interpret JSON. Tables are self-describing, so you can use standard tools like SQL engines or Spark to analyze your data.
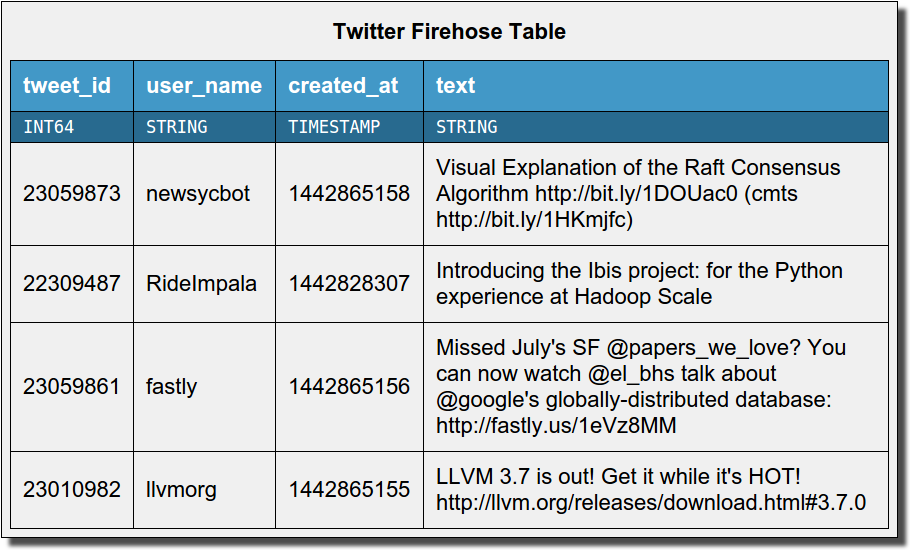
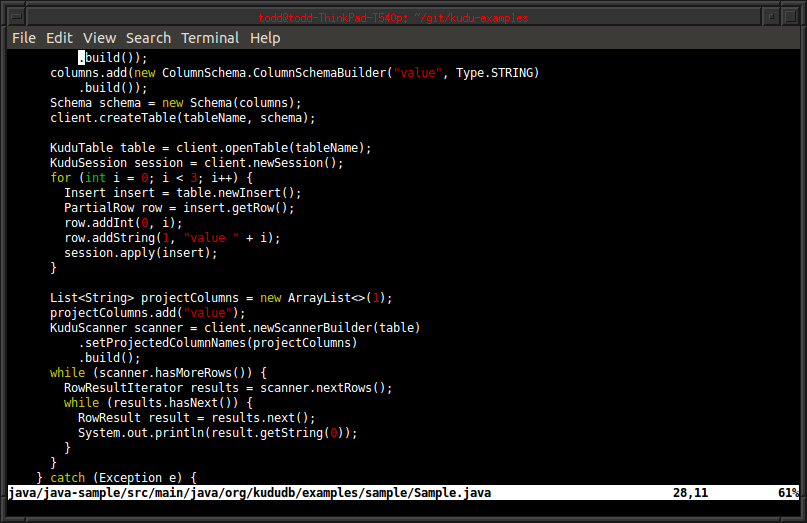
Low-latency random access
Unlike other storage for big data analytics, Kudu isn't just a file format. It's a live storage system which supports low-latency millisecond-scale access to individual rows. For "NoSQL"-style access, you can choose between Java, C++, or Python APIs. And of course these random access APIs can be used in conjunction with batch access for machine learning or analytics.
Kudu's APIs are designed to be easy to use. The data model is fully typed, so you don't need to worry about binary encodings or exotic serialization. You can just store primitive types, like when you use JDBC or ODBC.
Kudu isn't designed to be an OLTP system, but if you have some subset of data which fits in memory, it offers competitive random access performance. We've measured 99th percentile latencies of 6ms or below using YCSB with a uniform random access workload over a billion rows. Being able to run low-latency online workloads on the same storage as back-end data analytics can dramatically simplify application architecture.
Apache Hadoop Ecosystem Integration
Kudu was designed to fit in with the Hadoop ecosystem, and integrating it with other data processing frameworks is simple. You can stream data in from live real-time data sources using the Java client, and then process it immediately upon arrival using Spark, Impala, or MapReduce. You can even transparently join Kudu tables with data stored in other Hadoop storage such as HDFS or HBase.
Kudu is a good citizen on a Hadoop cluster: it can easily share data disks with HDFS DataNodes, and can operate in a RAM footprint as small as 1 GB for light workloads.
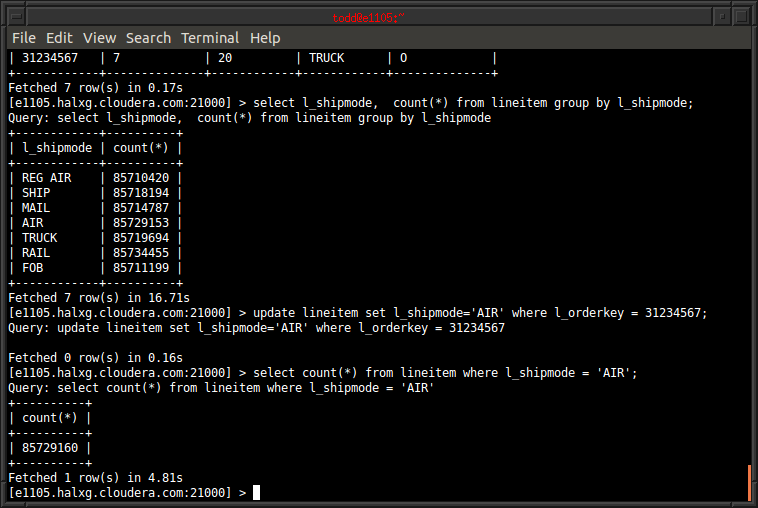
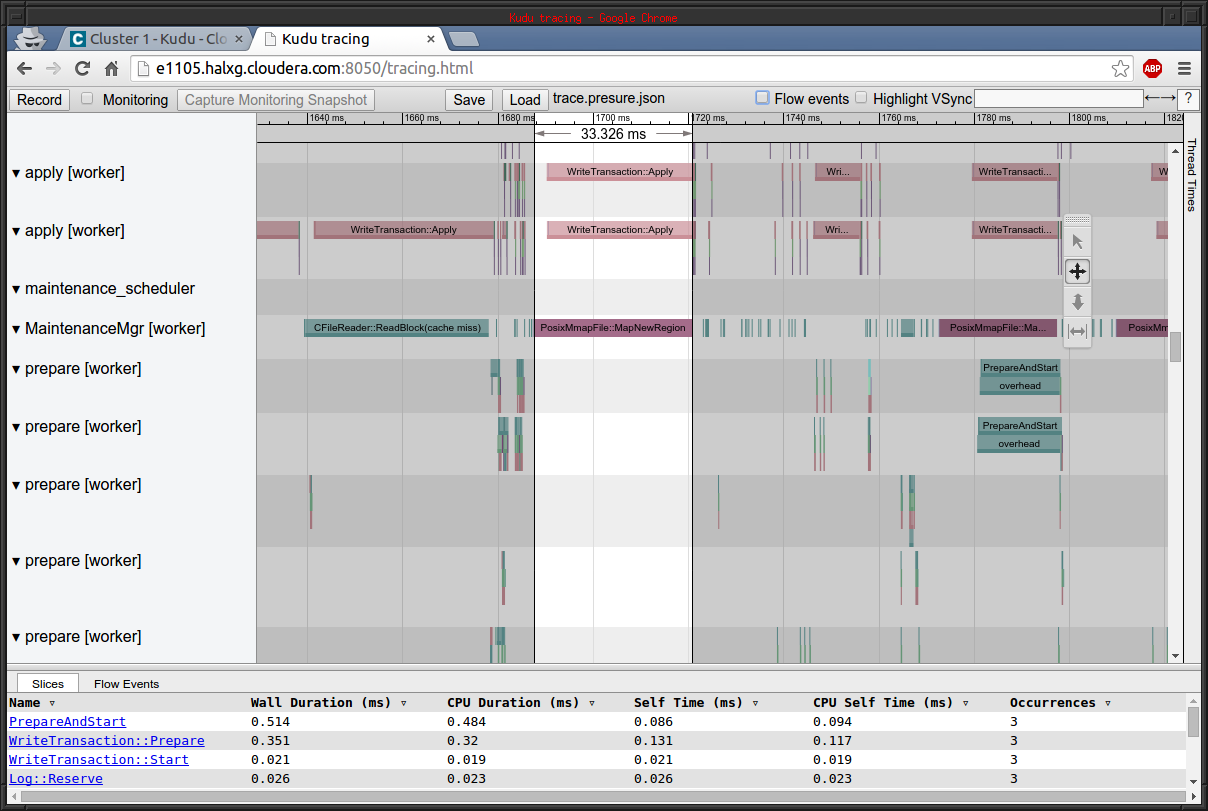
Built by and for Operators
Kudu was built by a group of engineers who have spent many late nights providing on-call production support for critical Hadoop clusters across hundreds of enterprise use cases. We know how frustrating it is to debug software without good metrics, tracing, or administrative tools.
Ever since its first beta release, Kudu has included advanced in-process tracing capabilities, extensive metrics support, and even watchdog threads which check for latency outliers and dump "smoking gun" stack traces to get to the root of the problem quickly.
Open Source
Kudu is Open Source software, licensed under the Apache 2.0 license and governed under the aegis of the Apache Software Foundation. We believe that Kudu's long-term success depends on building a vibrant community of developers and users from diverse organizations and backgrounds.
Super-fast Columnar Storage
Like most modern analytic data stores, Kudu internally organizes its data by column rather than row. Columnar storage allows efficient encoding and compression. For example, a string field with only a few unique values can use only a few bits per row of storage. With techniques such as run-length encoding, differential encoding, and vectorized bit-packing, Kudu is as fast at reading the data as it is space-efficient at storing it.
Columnar storage also dramatically reduces the amount of data IO required to service analytic queries. Using techniques such as lazy data materialization and predicate pushdown, Kudu can perform drill-down and needle-in-a-haystack queries over billions of rows and terabytes of data in seconds.

Distribution and Fault Tolerance
In order to scale out to large datasets and large clusters, Kudu splits tables into smaller units called tablets. This splitting can be configured on a per-table basis to be based on hashing, range partitioning, or a combination thereof. This allows the operator to easily trade off between parallelism for analytic workloads and high concurrency for more online ones.
In order to keep your data safe and available at all times, Kudu uses the Raft consensus algorithm to replicate all operations for a given tablet. Raft, like Paxos, ensures that every write is persisted by at least two nodes before responding to the client request, ensuring that no data is ever lost due to a machine failure. When machines do fail, replicas reconfigure themselves within a few seconds to maintain extremely high system availability.
The use of majority consensus provides very low tail latencies even when some nodes may be stressed by concurrent workloads such as Spark jobs or heavy Impala queries. But unlike eventually consistent systems, Raft consensus ensures that all replicas will come to agreement around the state of the data, and by using a combination of logical and physical clocks, Kudu can offer strict snapshot consistency to clients that demand it.
Designed for Next-Generation Hardware
The Kudu team has worked closely with engineers at Intel to harness the power of the next generation of hardware technologies. Kudu's storage is designed to take advantage of the IO characteristics of solid state drives, and it includes an experimental cache implementation based on the libpmem library which can store data in persistent memory.
Kudu is implemented in C++, so it can scale easily to large amounts of memory per node. And because key storage data structures are designed to be highly concurrent, it can scale easily to tens of cores. With an in-memory columnar execution path, Kudu achieves good instruction-level parallelism using SIMD operations from the SSE4 and AVX instruction sets.