Note: This is a cross-post from the Cloudera Engineering Blog Fine-Grained Authorization with Apache Kudu and Impala
Apache Impala supports fine-grained authorization via Apache Sentry on all of the tables it manages including Apache Kudu tables. Given Impala is a very common way to access the data stored in Kudu, this capability allows users deploying Impala and Kudu to fully secure the Kudu data in multi-tenant clusters even though Kudu does not yet have native fine-grained authorization of its own. This solution works because Kudu natively supports coarse-grained (all or nothing) authorization which enables blocking all access to Kudu directly except for the impala user and an optional whitelist of other trusted users. This post will describe how to use Apache Impala’s fine-grained authorization support along with Apache Kudu’s coarse-grained authorization to achieve a secure multi-tenant deployment.
Sample Workflow
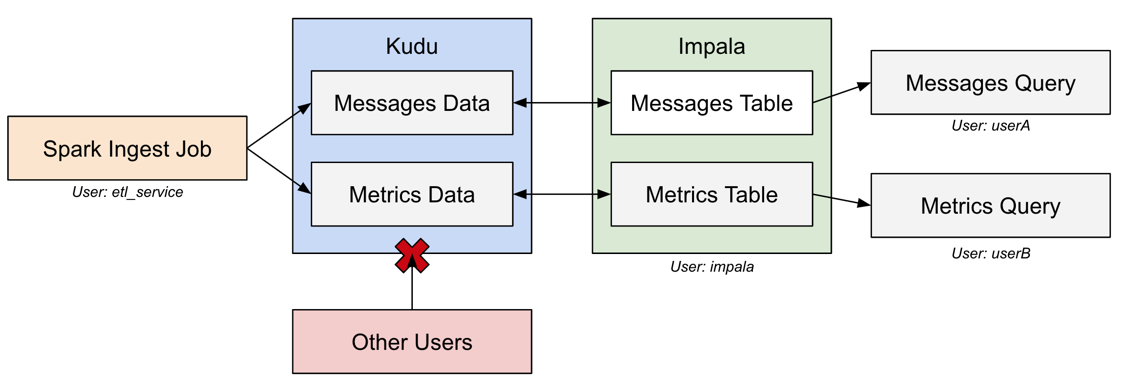
The examples in this post enable a workflow that uses Apache Spark to ingest data directly into
Kudu and Impala to run analytic queries on that data. The Spark job, run as the etl_service user,
is permitted to access the Kudu data via coarse-grained authorization. Even though this gives
access to all the data in Kudu, the etl_service user is only used for scheduled jobs or by an
administrator. All queries on the data, from a wide array of users, will use Impala and leverage
Impala’s fine-grained authorization. Impala’s
GRANT statements
allow you to flexibly control the privileges on the Kudu storage tables. Impala’s fine-grained
privileges along with support for
SELECT,
INSERT,
UPDATE,
UPSERT,
and DELETE
statements, allow you to finely control who can read and write data to your Kudu tables while
using Impala. Below is a diagram showing the workflow described:
Note: The examples below assume that Authorization has already been configured for Kudu, Impala, and Spark. For help configuring authorization see the Cloudera authorization documentation.
Configuring Kudu’s Coarse-Grained Authorization
Kudu supports coarse-grained authorization of client requests based on the authenticated client Kerberos principal. The two levels of access which can be configured are:
- Superuser – principals authorized as a superuser are able to perform certain administrative functionality such as using the kudu command line tool to diagnose or repair cluster issues.
- User – principals authorized as a user are able to access and modify all data in the Kudu cluster. This includes the ability to create, drop, and alter tables as well as read, insert, update, and delete data.
Access levels are granted using whitelist-style Access Control Lists (ACLs), one for each of the
two levels. Each access control list either specifies a comma-separated list of users, or may be
set to * to indicate that all authenticated users are able to gain access at the specified level.
Note: The default value for the User ACL is *, which allows all users access to the cluster.
Example Configuration
The first and most important step is to remove the default ACL of * from Kudu’s
–user_acl configuration.
This will ensure only the users you list will have access to the Kudu cluster. Then, to allow the
Impala service to access all of the data in Kudu, the Impala service user, usually impala, should
be added to the Kudu –user_acl configuration. Any user that is not using Impala will also need
to be added to this list. For example, an Apache Spark job might be used to load data directly
into Kudu. Generally, a single user is used to run scheduled jobs of applications that do not
support fine-grained authorization on their own. For this example, that user is etl_service. The
full –user_acl configuration is:
--user_acl=impala,etl_serviceFor more details see the Kudu authorization documentation.
Using Impala’s Fine-Grained Authorization
Follow Impala’s
authorization documentation
to configure fine-grained authorization. Once configured, you can use Impala’s
GRANT statements
to control the privileges of Kudu tables. These fine-grained privileges can be set at the database,
table and column level. Additionally you can individually control SELECT, INSERT, CREATE,
ALTER, and DROP privileges.
Note: A user needs the ALL privilege in order to run DELETE, UPDATE, or UPSERT
statements against a Kudu table.
Below is a brief example with a couple tables stored in Kudu:
CREATE TABLE messages
(
name STRING,
time TIMESTAMP,
message STRING,
PRIMARY KEY(name, time)
)
PARTITION BY HASH(name) PARTITIONS 4
STORED AS KUDU;
GRANT ALL ON TABLE messages TO userA;
CREATE TABLE metrics
(
host STRING NOT NULL,
metric STRING NOT NULL,
time INT64 NOT NULL,
value DOUBLE NOT NULL,
PRIMARY KEY (host, metric, time)
)
PARTITION BY HASH(name) PARTITIONS 4
STORED AS KUDU;
GRANT ALL ON TABLE messages TO userB;Conclusion
This brief example that combines Kudu’s coarse-grained authorization and Impala’s fine-grained authorization should enable you to meet the security needs of your data workflow today. The pattern described here can be applied to other services and workflows using Kudu as well. For greater authorization flexibility, you can look forward to the near future when Kudu supports native fine-grained authorization on its own. The Apache Kudu contributors understand the importance of native fine-grained authorization and they are working on integrations with Apache Sentry and Apache Ranger.