Note: This is a cross-post from the Cloudera Engineering Blog Transparent Hierarchical Storage Management with Apache Kudu and Impala
When picking a storage option for an application it is common to pick a single storage option which has the most applicable features to your use case. For mutability and real-time analytics workloads you may want to use Apache Kudu, but for massive scalability at a low cost you may want to use HDFS. For that reason, there is a need for a solution that allows you to leverage the best features of multiple storage options. This post describes the sliding window pattern using Apache Impala with data stored in Apache Kudu and Apache HDFS. With this pattern you get all of the benefits of multiple storage layers in a way that is transparent to users.
Apache Kudu is designed for fast analytics on rapidly changing data. Kudu provides a combination of fast inserts/updates and efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer. For that reason, Kudu fits well into a data pipeline as the place to store real-time data that needs to be queryable immediately. Additionally, Kudu supports updating and deleting rows in real-time allowing support for late arriving data and data correction.
Apache HDFS is designed to allow for limitless scalability at a low cost. It is optimized for batch oriented use cases where data is immutable. When paired with the Apache Parquet file format, structured data can be accessed with extremely high throughput and efficiency.
For situations in which the data is small and ever-changing, like dimension tables, it is common to keep all of the data in Kudu. It is even common to keep large tables in Kudu when the data fits within Kudu’s scaling limits and can benefit from Kudu’s unique features. In cases where the data is massive, batch oriented, and unlikely to change, storing the data in HDFS using the Parquet format is preferred. When you need the benefits of both storage layers, the sliding window pattern is a useful solution.
The Sliding Window Pattern
In this pattern, matching Kudu and Parquet formatted HDFS tables are created in Impala.
These tables are partitioned by a unit of time based on how frequently the data is
moved between the Kudu and HDFS table. It is common to use daily, monthly, or yearly
partitions. A unified view is created and a WHERE clause is used to define a boundary
that separates which data is read from the Kudu table and which is read from the HDFS
table. The defined boundary is important so that you can move data between Kudu and
HDFS without exposing duplicate records to the view. Once the data is moved, an atomic
ALTER VIEW statement can be used to move the boundary forward.
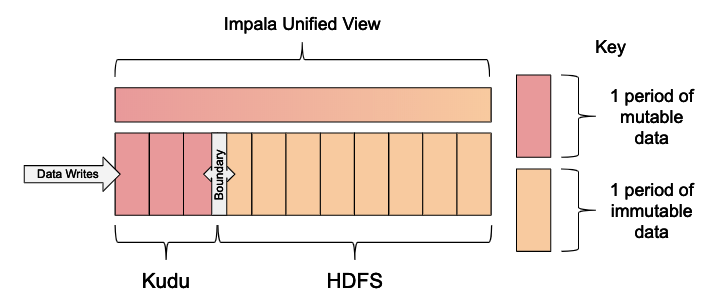
Note: This pattern works best with somewhat sequential data organized into range partitions, because having a sliding window of time and dropping partitions is very efficient.
This pattern results in a sliding window of time where mutable data is stored in Kudu and immutable data is stored in the Parquet format on HDFS. Leveraging both Kudu and HDFS via Impala provides the benefits of both storage systems:
- Streaming data is immediately queryable
- Updates for late arriving data or manual corrections can be made
- Data stored in HDFS is optimally sized increasing performance and preventing small files
- Reduced cost
Impala also supports cloud storage options such as S3 and ADLS. This capability allows convenient access to a storage system that is remotely managed, accessible from anywhere, and integrated with various cloud-based services. Because this data is remote, queries against S3 data are less performant, making S3 suitable for holding “cold” data that is only queried occasionally. This pattern can be extended to use cloud storage for cold data by creating a third matching table and adding another boundary to the unified view.
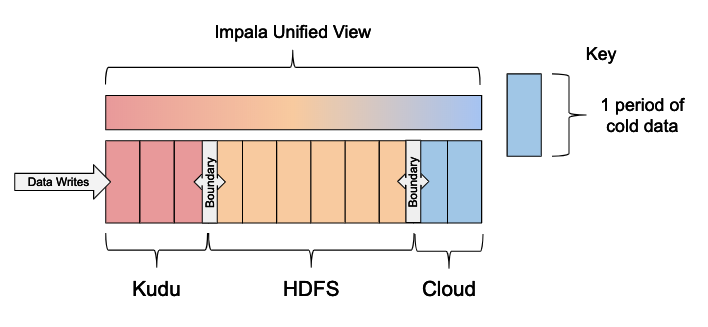
Note: For simplicity only Kudu and HDFS are illustrated in the examples below.
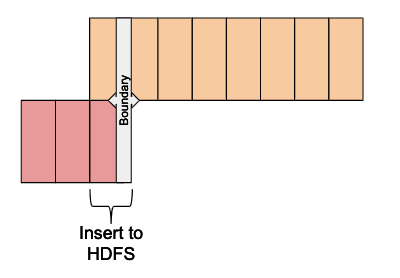
The process for moving data from Kudu to HDFS is broken into two phases. The first phase is the data migration, and the second phase is the metadata change. These ongoing steps should be scheduled to run automatically on a regular basis.
In the first phase, the now immutable data is copied from Kudu to HDFS. Even though data is duplicated from Kudu into HDFS, the boundary defined in the view will prevent duplicate data from being shown to users. This step can include any validation and retries as needed to ensure the data offload is successful.
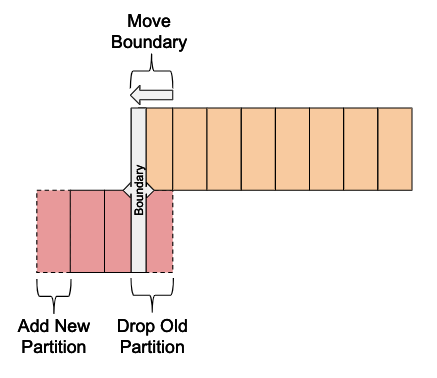
In the second phase, now that the data is safely copied to HDFS, the metadata is changed to adjust how the offloaded partition is exposed. This includes shifting the boundary forward, adding a new Kudu partition for the next period, and dropping the old Kudu partition.
Building Blocks
In order to implement the sliding window pattern, a few Impala fundamentals are required. Below each fundamental building block of the sliding window pattern is described.
Moving Data
Moving data among storage systems via Impala is straightforward provided you have matching tables defined using each of the storage formats. In order to keep this post brief, all of the options available when creating an Impala table are not described. However, Impala’s CREATE TABLE documentation can be referenced to find the correct syntax for Kudu, HDFS, and cloud storage tables. A few examples are shown further below where the sliding window pattern is illustrated.
Once the tables are created, moving the data is as simple as an INSERT…SELECT statement:
INSERT INTO table_foo
SELECT * FROM table_bar;All of the features of the SELECT statement can be used to select the specific data you would like to move.
Note: If moving data to Kudu, an UPSERT INTO statement can be used to handle
duplicate keys.
Unified Querying
Querying data from multiple tables and data sources in Impala is also straightforward. For the sake of brevity, all of the options available when creating an Impala view are not described. However, see Impala’s CREATE VIEW documentation for more in-depth details.
Creating a view for unified querying is as simple as a CREATE VIEW statement using
two SELECT clauses combined with a UNION ALL:
CREATE VIEW foo_view AS
SELECT col1, col2, col3 FROM foo_parquet
UNION ALL
SELECT col1, col2, col3 FROM foo_kudu;WARNING: Be sure to use UNION ALL and not UNION. The UNION keyword by itself
is the same as UNION DISTINCT and can have significant performance impact.
More information can be found in the Impala
UNION documentation.
All of the features of the
SELECT
statement can be used to expose the correct data and columns from each of the
underlying tables. It is important to use the WHERE clause to pass through and
pushdown any predicates that need special handling or transformations. More examples
will follow below in the discussion of the sliding window pattern.
Additionally, views can be altered via the
ALTER VIEW
statement. This is useful when combined with the SELECT statement because it can be
used to atomically update what data is being accessed by the view.
An Example Implementation
Below are sample steps to implement the sliding window pattern using a monthly period with three months of active mutable data. Data older than three months will be offloaded to HDFS using the Parquet format.
Create the Kudu Table
First, create a Kudu table which will hold three months of active mutable data.
The table is range partitioned by the time column with each range containing one
period of data. It is important to have partitions that match the period because
dropping Kudu partitions is much more efficient than removing the data via the
DELETE clause. The table is also hash partitioned by the other key column to ensure
that all of the data is not written to a single partition.
Note: Your schema design should vary based on your data and read/write performance considerations. This example schema is intended for demonstration purposes and not as an “optimal” schema. See the Kudu schema design documentation for more guidance on choosing your schema. For example, you may not need any hash partitioning if your data input rate is low. Alternatively, you may need more hash buckets if your data input rate is very high.
CREATE TABLE my_table_kudu
(
name STRING,
time TIMESTAMP,
message STRING,
PRIMARY KEY(name, time)
)
PARTITION BY
HASH(name) PARTITIONS 4,
RANGE(time) (
PARTITION '2018-01-01' <= VALUES < '2018-02-01', --January
PARTITION '2018-02-01' <= VALUES < '2018-03-01', --February
PARTITION '2018-03-01' <= VALUES < '2018-04-01', --March
PARTITION '2018-04-01' <= VALUES < '2018-05-01' --April
)
STORED AS KUDU;Note: There is an extra month partition to provide a buffer of time for the data to be moved into the immutable table.
Create the HDFS Table
Create the matching Parquet formatted HDFS table which will hold the older immutable data. This table is partitioned by year, month, and day for efficient access even though you can’t partition by the time column itself. This is addressed further in the view step below. See Impala’s partitioning documentation for more details.
CREATE TABLE my_table_parquet
(
name STRING,
time TIMESTAMP,
message STRING
)
PARTITIONED BY (year int, month int, day int)
STORED AS PARQUET;Create the Unified View
Now create the unified view which will be used to query all of the data seamlessly:
CREATE VIEW my_table_view AS
SELECT name, time, message
FROM my_table_kudu
WHERE time >= "2018-01-01"
UNION ALL
SELECT name, time, message
FROM my_table_parquet
WHERE time < "2018-01-01"
AND year = year(time)
AND month = month(time)
AND day = day(time);Each SELECT clause explicitly lists all of the columns to expose. This ensures that
the year, month, and day columns that are unique to the Parquet table are not exposed.
If needed, it also allows any necessary column or type mapping to be handled.
The initial WHERE clauses applied to both my_table_kudu and my_table_parquet define
the boundary between Kudu and HDFS to ensure duplicate data is not read while in the
process of offloading data.
The additional AND clauses applied to my_table_parquet are used to ensure good
predicate pushdown on the individual year, month, and day columns.
WARNING: As stated earlier, be sure to use UNION ALL and not UNION. The UNION
keyword by itself is the same as UNION DISTINCT and can have significant performance
impact. More information can be found in the Impala
UNION documentation.
Ongoing Steps
Now that the base tables and view are created, prepare the ongoing steps to maintain
the sliding window. Because these ongoing steps should be scheduled to run on a
regular basis, the examples below are shown using .sql files that take variables
which can be passed from your scripts and scheduling tool of choice.
Create the window_data_move.sql file to move the data from the oldest partition to HDFS:
INSERT INTO ${var:hdfs_table} PARTITION (year, month, day)
SELECT *, year(time), month(time), day(time)
FROM ${var:kudu_table}
WHERE time >= add_months("${var:new_boundary_time}", -1)
AND time < "${var:new_boundary_time}";
COMPUTE INCREMENTAL STATS ${var:hdfs_table};Note: The COMPUTE INCREMENTAL STATS clause is not required but helps Impala to optimize queries.
To run the SQL statement, use the Impala shell and pass the required variables. Below is an example:
impala-shell -i <impalad:port> -f window_data_move.sql
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"Note: You can adjust the WHERE clause to match the given period and cadence of your
offload. Here the add_months function is used with an argument of -1 to move one month
of data in the past from the new boundary time.
Create the window_view_alter.sql file to shift the time boundary forward by altering
the unified view:
ALTER VIEW ${var:view_name} AS
SELECT name, time, message
FROM ${var:kudu_table}
WHERE time >= "${var:new_boundary_time}"
UNION ALL
SELECT name, time, message
FROM ${var:hdfs_table}
WHERE time < "${var:new_boundary_time}"
AND year = year(time)
AND month = month(time)
AND day = day(time);To run the SQL statement, use the Impala shell and pass the required variables. Below is an example:
impala-shell -i <impalad:port> -f window_view_alter.sql
--var=view_name=my_table_view
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"Create the window_partition_shift.sql file to shift the Kudu partitions forward:
ALTER TABLE ${var:kudu_table}
ADD RANGE PARTITION add_months("${var:new_boundary_time}",
${var:window_length}) <= VALUES < add_months("${var:new_boundary_time}",
${var:window_length} + 1);
ALTER TABLE ${var:kudu_table}
DROP RANGE PARTITION add_months("${var:new_boundary_time}", -1)
<= VALUES < "${var:new_boundary_time}";To run the SQL statement, use the Impala shell and pass the required variables. Below is an example:
impala-shell -i <impalad:port> -f window_partition_shift.sql
--var=kudu_table=my_table_kudu
--var=new_boundary_time="2018-02-01"
--var=window_length=3Note: You should periodically run COMPUTE STATS on your Kudu table to ensure Impala’s query performance is optimal.
Experimentation
Now that you have created the tables, view, and scripts to leverage the sliding window pattern, you can experiment with them by inserting data for different time ranges and running the scripts to move the window forward through time.
Insert some sample values into the Kudu table:
INSERT INTO my_table_kudu VALUES
('joey', '2018-01-01', 'hello'),
('ross', '2018-02-01', 'goodbye'),
('rachel', '2018-03-01', 'hi');Show the data in each table/view:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;Move the January data into HDFS:
impala-shell -i <impalad:port> -f window_data_move.sql
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"Confirm the data is in both places, but not duplicated in the view:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;Alter the view to shift the time boundary forward to February:
impala-shell -i <impalad:port> -f window_view_alter.sql
--var=view_name=my_table_view
--var=kudu_table=my_table_kudu
--var=hdfs_table=my_table_parquet
--var=new_boundary_time="2018-02-01"Confirm the data is still in both places, but not duplicated in the view:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;Shift the Kudu partitions forward:
impala-shell -i <impalad:port> -f window_partition_shift.sql
--var=kudu_table=my_table_kudu
--var=new_boundary_time="2018-02-01"
--var=window_length=3Confirm the January data is now only in HDFS:
SELECT * FROM my_table_kudu;
SELECT * FROM my_table_parquet;
SELECT * FROM my_table_view;Confirm predicate push down with Impala’s EXPLAIN statement:
EXPLAIN SELECT * FROM my_table_view;
EXPLAIN SELECT * FROM my_table_view WHERE time < "2018-02-01";
EXPLAIN SELECT * FROM my_table_view WHERE time > "2018-02-01";In the explain output you should see “kudu predicates” which include the time column filters in the “SCAN KUDU” section and “predicates” which include the time, day, month, and year columns in the “SCAN HDFS” section.