This summer I got the opportunity to intern with the Apache Kudu team at Cloudera. My project was to optimize the Kudu scan path by implementing a technique called index skip scan (a.k.a. scan-to-seek, see section 4.1 in [1]). I wanted to share my experience and the progress we’ve made so far on the approach.
Let’s begin with discussing the current query flow in Kudu. Consider the following table:
CREATE TABLE metrics (
host STRING,
tstamp INT,
clusterid INT,
role STRING,
PRIMARY KEY (host, tstamp, clusterid)
);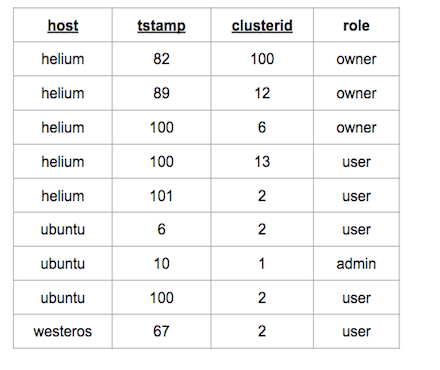 Sample rows of table
Sample rows of table metrics (sorted by key columns).
In this case, by default, Kudu internally builds a primary key index (implemented as a
B-tree) for the table metrics.
As shown in the table above, the index data is sorted by the composite of all key columns.
When the user query contains the first key column (host), Kudu uses the index (as the index data is
primarily sorted on the first key column).
Now, what if the user query does not contain the first key column and instead only contains the tstamp column?
In the above case, the tstamp column values are sorted with respect to host,
but are not globally sorted, and as such, it’s non-trivial to use the index to filter rows.
Instead, a full tablet scan is done by default. Other databases may optimize such scans by building secondary indexes
(though it might be redundant to build one on one of the primary keys). However, this isn’t an option for Kudu,
given its lack of secondary index support.
The question is, can Kudu do better than a full tablet scan here?
The answer is yes! Let’s observe the column preceding the tstamp column. We will refer to it as the
“prefix column” and its specific value as the “prefix key”. In this example, host is the prefix column.
Note that the prefix keys are sorted in the index and that all rows of a given prefix key are also sorted by the
remaining key columns. Therefore, we can use the index to skip to the rows that have distinct prefix keys,
and also satisfy the predicate on the tstamp column.
For example, consider the query:
SELECT clusterid FROM metrics WHERE tstamp = 100;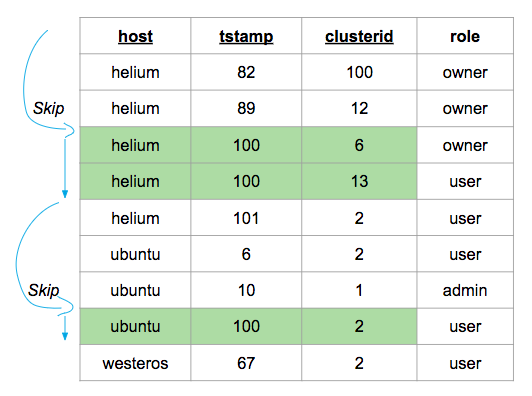 Skip scan flow illustration. The rows in green are scanned and the rest are skipped.
Skip scan flow illustration. The rows in green are scanned and the rest are skipped.
The tablet server can use the index to skip to the first row with a distinct prefix key (host = helium) that
matches the predicate (tstamp = 100) and then scan through the rows until the predicate no longer matches. At that
point we would know that no more rows with host = helium will satisfy the predicate, and we can skip to the next
prefix key. This holds true for all distinct keys of host. Hence, this method is popularly known as
skip scan optimization[2, 3].
Performance
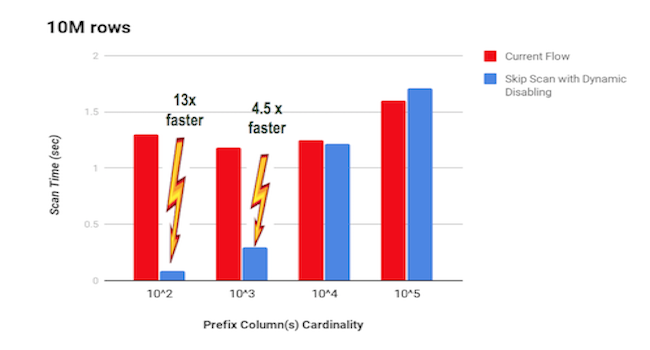
This optimization can speed up queries significantly, depending on the cardinality (number of distinct values) of the prefix column. The lower the prefix column cardinality, the better the skip scan performance. In fact, when the prefix column cardinality is high, skip scan is not a viable approach. The performance graph (obtained using the example schema and query pattern mentioned earlier) is shown below.
Based on our experiments, on up to 10 million rows per tablet (as shown below), we found that the skip scan performance begins to get worse with respect to the full tablet scan performance when the prefix column cardinality exceeds sqrt(number_of_rows_in_tablet). Therefore, in order to use skip scan performance benefits when possible and maintain a consistent performance in cases of large prefix column cardinality, we have tentatively chosen to dynamically disable skip scan when the number of skips for distinct prefix keys exceeds sqrt(number_of_rows_in_tablet). It will be an interesting project to further explore sophisticated heuristics to decide when to dynamically disable skip scan.
Conclusion
Skip scan optimization in Kudu can lead to huge performance benefits that scale with the size of
data in Kudu tablets. This is a work-in-progress patch.
The implementation in the patch works only for equality predicates on the non-first primary key
columns. An important point to note is that although, in the above specific example, the number of prefix
columns is one (host), this approach is generalized to work with any number of prefix columns.
This work also lays the groundwork to leverage the skip scan approach and optimize query processing time in the following use cases:
- Range predicates
- In-list predicates
This was my first time working on an open source project. I thoroughly enjoyed working on this challenging problem, right from understanding the scan path in Kudu to working on a full-fledged implementation of the skip scan optimization. I am very grateful to the Kudu team for guiding and supporting me throughout the internship period.
References
[1]: Gupta, Ashish, et al. “Mesa: Geo-replicated, near real-time, scalable data warehousing.” Proceedings of the VLDB Endowment 7.12 (2014): 1259-1270.
[2]: Index Skip Scanning - Oracle Database
[3]: Skip Scan - SQLite