I had the pleasure of interning with the Apache Kudu team at Cloudera this summer. This project was my summer contribution to Kudu: a restructuring of the scan path to speed up queries.
Introduction
In Kudu, predicate pushdown refers to the way in which predicates are handled. When a scan is requested, its predicates are passed through the different layers of Kudu’s storage hierarchy, allowing for pruning and other optimizations to happen at each level before reaching the underlying data.
While predicates are pushed down, predicate evaluation itself occurs at a fairly high level, precluding the evaluation process from certain data-specific optimizations. These optimizations can make tablet scans an order of magnitude faster, if not more.
A Day in the Life of a Query
Because Kudu is a columnar storage engine, its scan path has a number of optimizations to avoid extraneous reads, copies, and computation. When a query is sent to a tablet server, the server prunes tablets based on the primary key, directing the request to only the tablets that contain the key range of interest. Once at a tablet, only the columns relevant to the query are scanned. Further pruning is done over the primary key, and if the query is predicated on non-key columns, the entire column is scanned. The columns in a tablet are stored as cfiles, which are split into encoded blocks. Once the relevant cfiles are determined, the data are materialized by the block decoders, i.e. their underlying data are decoded and copied into a buffer, which is passed back to the tablet layer. The tablet can then evaluate the predicate on the batch of data and mark which rows should be returned to the client.
One of the encoding types I worked very closely with is dictionary encoding, an encoding type for strings that performs particularly well for cfiles that have repeating values. Rather than storing every row’s string, each unique string is assigned a numeric codeword, and the rows are stored numerically on disk. When materializing a dictionary block, all of the numeric data are scanned and all of the corresponding strings are copied and buffered for evaluation. When the vocabulary of a dictionary-encoded cfile gets too large, the blocks begin switching to plain encoding mode to act like plain-encoded blocks.
In a plain-encoded block, strings are stored contiguously and the character offsets to the start of each string are stored as a list of integers. When materializing, all of the strings are copied to a buffer for evaluation.
Therein lies room for improvement: this predicate evaluation path is the same for all data types and encoding types. Within the tablet, the correct cfiles are determined, the cfiles’ decoders are opened, all of the data are copied to a buffer, and the predicates are evaluated on this buffered data via type-specific comparators. This path is extremely flexible, but because it was designed to be encoding-independent, there is room for improvement.
Trimming the Fat
The first step is to allow the decoders access to the predicate. In doing so, each encoding type can specialize its evaluation. Additionally, this puts the decoder in a position where it can determine whether a given row satisfies the query, which in turn, allows the decoders to determine what data gets copied instead of eagerly copying all of its data to get evaluated.
Take the case of dictionary-encoded strings as an example. With the existing scan path, not only are all of the strings in a column copied into a buffer, but string comparisons are done on every row. By taking advantage of the fact that the data can be represented as integers, the cost of determining the query results can be greatly reduced. The string comparisons can be swapped out with evaluation based on the codewords, in which case the room for improvement boils down to how to most quickly determine whether or not a given codeword corresponds to a string that satisfies the predicate. Dictionary columns will now use a bitset to store the codewords that match the predicates. It will then scan through the integer-valued data and checks the bitset to determine whether it should copy the corresponding string over.
This is great in the best case scenario where a cfile’s vocabulary is small, but when the vocabulary gets too large and the dictionary blocks switch to plain encoding mode, performance is hampered. In this mode, the blocks don’t utilize any dictionary metadata and end up wasting the codeword bitset. That isn’t to say all is lost: the decoders can still evaluate a predicate via string comparison, and the fact that evaluation can still occur at the decoder-level means the eager buffering can still be avoided.
Dictionary encoding is a perfect storm in that the decoders can completely evaluate the predicates. This is not the case for most other encoding types, but having decoders support evaluation leaves the door open for other encoding types to extend this idea.
Performance
Depending on the dataset and query, predicate pushdown can lead to significant improvements. Tablet scans were timed with datasets consisting of repeated string patterns of tunable length and tunable cardinality.
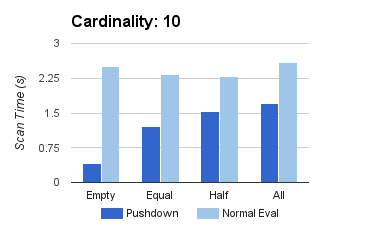
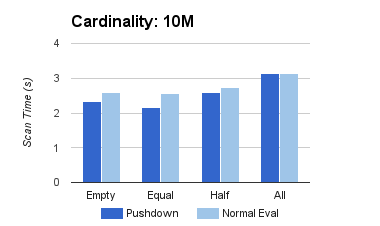
The above plots show the time taken to completely scan a single tablet, recorded using a dataset of ten million rows of strings with length ten. Predicates were designed to select values out of bounds (Empty), select a single value (Equal, i.e. for cardinality k, this would select 1/k of the dataset), select half of the full range (Half), and select the full range of values (All).
With the original evaluation implementation, the tablet must copy and scan through the tablet to determine whether any values match. This means that even when the result set is small, the full column is still copied. This is avoided by pushing down predicates, which only copies as needed, and can be seen in the above queries: those with near-empty result sets (Empty and Equal) have shorter scan times than those with larger result sets (Half and All).
Note that for dictionary encoding, given a low cardinality, Kudu can completely rely on the dictionary codewords to evaluate, making the query significantly faster. At higher cardinalities, the dictionaries completely fill up and the blocks fall back on plain encoding. The slower, albeit still improved, performance on the dataset containing 10M unique values reflects this.
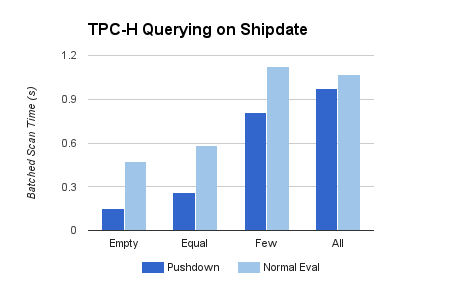
Similar predicates were run with the TPC-H dataset, querying on the shipdate column. The full path of a query includes not only the tablet scanning itself, but also RPCs and batched data transfer to the caller as the scan progresses. As such, the times plotted above refer to the average end-to-end time required to scan and return a batch of rows. Regardless of this additional overhead, significant improvements on the scan path still yield substantial improvements to the query performance as a whole.
Conclusion
Pushing down predicate evaluation in Kudu yielded substantial improvements to the scan path. For dictionary encoding, pushdown can be particularly powerful, and other encoding types are either unaffected or also improved. This change has been pushed to the main branch of Kudu, and relevant commits can be found here and here.
This summer has been a phenomenal learning experience for me, in terms of the tools, the workflow, the datasets, the thought-processes that go into building something at Kudu’s scale. I am extremely thankful for all of the mentoring and support I received, and that I got to be a part of Kudu’s journey from incubating to a Top Level Apache project. I can’t express enough how grateful I am for the amount of support I got from the Kudu team, from the intern coordinators, and from the Cloudera community as a whole.