Kudu 0.10 is shipping with a few important new features for range partitioning. These features are designed to make Kudu easier to scale for certain workloads, like time series. This post will introduce these features, and discuss how to use them to effectively design tables for scalability and performance.
Since Kudu’s initial release, tables have had the constraint that once created, the set of partitions is static. This forces users to plan ahead and create enough partitions for the expected size of the table, because once the table is created no further partitions can be added. When using hash partitioning, creating more partitions is as straightforward as specifying more buckets. For range partitioning, however, knowing where to put the extra partitions ahead of time can be difficult or impossible.
The common solution to this problem in other distributed databases is to allow range partitions to split into smaller child range partitions. Unfortunately, range splitting typically has a large performance impact on running tables, since child partitions need to eventually be recompacted and rebalanced to a remote server. Range splitting is particularly thorny with Kudu, because rows are stored in tablets in primary key sorted order, which does not necessarily match the range partitioning order. If the range partition key is different than the primary key, then splitting requires inspecting and shuffling each individual row, instead of splitting the tablet in half.
Adding and Dropping Range Partitions
As an alternative to range partition splitting, Kudu now allows range partitions to be added and dropped on the fly, without locking the table or otherwise affecting concurrent operations on other partitions. This solution is not strictly as powerful as full range partition splitting, but it strikes a good balance between flexibility, performance, and operational overhead. Additionally, this feature does not preclude range splitting in the future if there is a push to implement it. To support adding and dropping range partitions, Kudu had to remove an even more fundamental restriction when using range partitions.
Previously, range partitions could only be created by specifying split points. Split points divide an implicit partition covering the entire range into contiguous and disjoint partitions. When using split points, the first and last partitions are always unbounded below and above, respectively. A consequence of the final partition being unbounded is that datasets which are range-partitioned on a column that increases in value over time will eventually have far more rows in the last partition than in any other. Unbalanced partitions are commonly referred to as hotspots, and until Kudu 0.10 they have been difficult to avoid when storing time series data in Kudu.
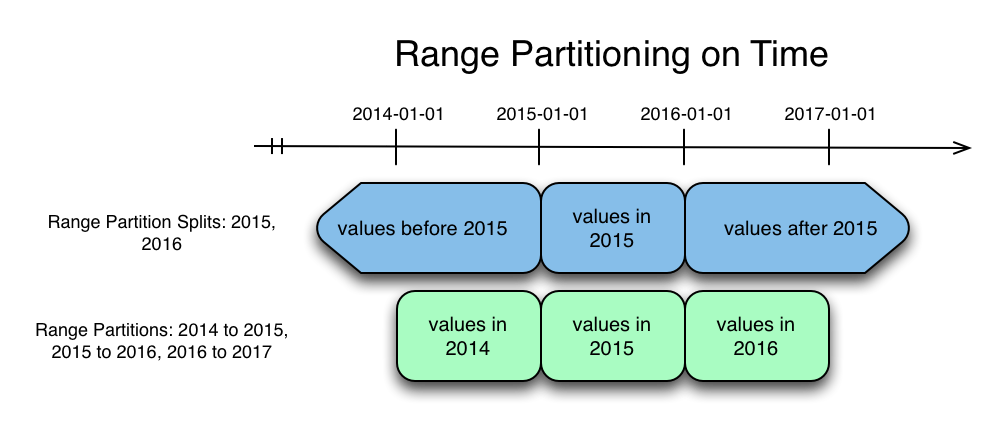
The figure above shows the tablets created by two different attempts to partition a table by range on a timestamp column. The first, above in blue, uses split points. The second, below in green, uses bounded range partitions specified during table creation. With bounded range partitions, there is no longer a guarantee that every possible row has a corresponding range partition. As a result, Kudu will now reject writes which fall in a ‘non-covered’ range.
Now that tables are no longer required to have range partitions covering all possible rows, Kudu can support adding range partitions to cover the otherwise unoccupied space. Dropping a range partition will result in unoccupied space where the range partition was previously. In the example above, we may want to add a range partition covering 2017 at the end of the year, so that we can continue collecting data in the future. By lazily adding range partitions we avoid hotspotting, avoid the need to specify range partitions up front for time periods far in the future, and avoid the downsides of splitting. Additionally, historical data which is no longer useful can be efficiently deleted by dropping the entire range partition.
What About Hash Partitioning?
Since Kudu’s hash partitioning feature originally shipped in version 0.6, it has been possible to create tables which combine hash partitioning with range partitioning. The new range partitioning features continue to work seamlessly when combined with hash partitioning. Just as before, the number of tablets which comprise a table will be the product of the number of range partitions and the number of hash partition buckets. Adding or dropping a range partition will result in the creation or deletion of one tablet per hash bucket.
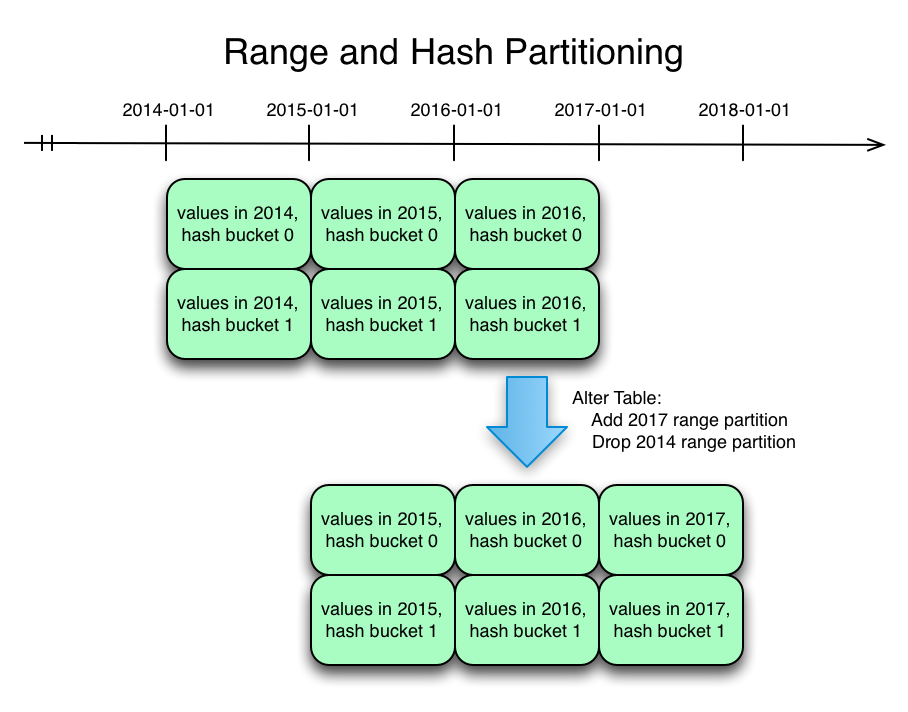
The diagram above shows a time series table range-partitioned on the timestamp and hash-partitioned with two buckets. The hash partitioning could be on the timestamp column, or it could be on any other column or columns in the primary key. In this example only two years of historical data is needed, so at the end of 2016 a new range partition is added for 2017 and the historical 2014 range partition is dropped. This causes two new tablets to be created for 2017, and the two existing tablets for 2014 to be deleted.
Getting Started
Beginning with the Kudu 0.10 release, users can add and drop range partitions through the Java and C++ client APIs. Range partitions on existing tables can be dropped and replacements added, but it requires the servers and all clients to be updated to 0.10.